Topics
The vanilla Transformer architecture introduced in “Attention Is All You Need” paper, was designed to address the limitations of limitations of recurrent neural networks in seq2seq modelling, particularly for machine translation. The Transformer achieved state-of-the-art results on WMT 2014 (machine translation benchmark), while requiring significantly less training time than recurrent approaches. Its success stems from three key innovations:
- Complete replacement of recurrence with self-attention
- multi-head attention allowing different representation subspaces
- Positional embeddings enabling sequence order awareness
The attention mechanism weighs the influence of different input parts on each output part. The original paper designed the architecture as:
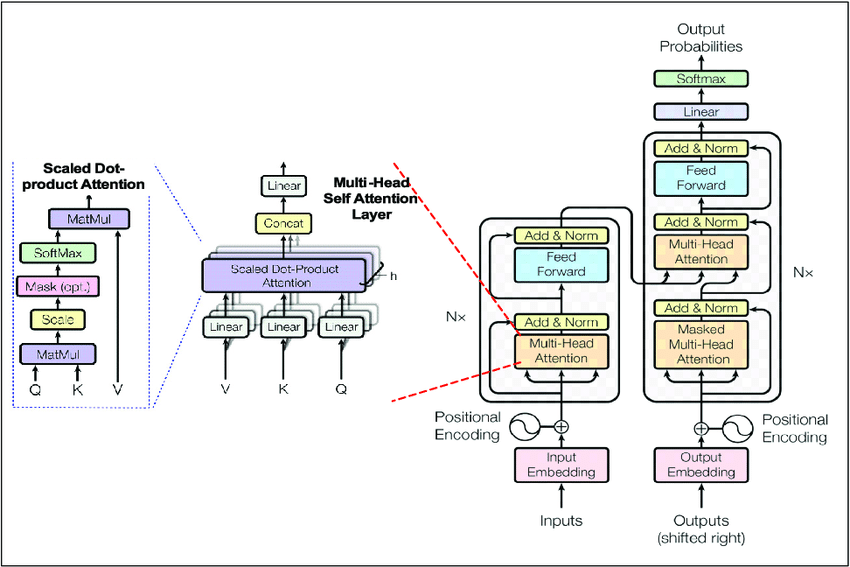
It follows the encoder-decoder architecture, as was originally used for machine translation task. The transformer encoder block contains:
- multi-head self-attention layer that computes attention weights between all positions
- feed forward layers to increase model capacity
- residual connection around each sub-layer followed by layer normalization (normalization technique to stabilize gradients)
The transformer decoder block has similar components but adds:
- masked multi-head self-attention (masking to prevent positions from attending to subsequent positions)
- cross-attention (via multi-head attention) to incorporate the encoder’s output: (K, V) come from encoder output, Q comes from decoder
Input processing involves:
- token embedding for sequence models to convert discrete tokens to continuous vectors
- encoding sequence position without recurrence via sinusoidal positional encoding or learned positional embeddings
The architecture’s design choices enable several benefits:
- parallel computation across sequence positions
- constant path length between any two positions (vs. in RNNs)
- direct modeling of long-range dependencies through attention
Plethora of applications: Machine translation, text summarization, NER, Question answering, text generation, chatbots, computer vision and more.