Topics
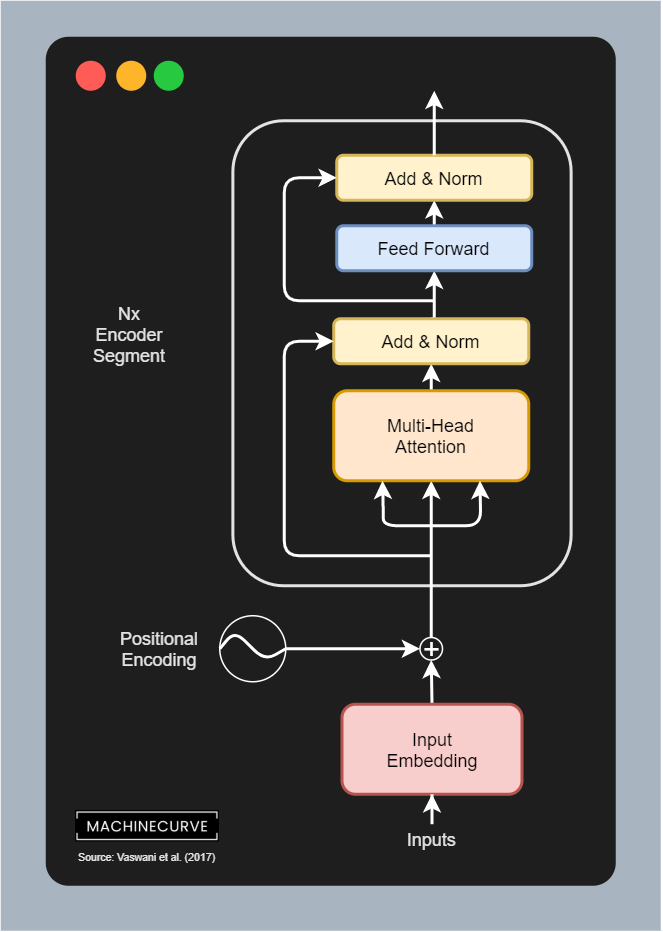
A standard Transformer encoder block is a fundamental component of the Transformer’s encoder. It takes an input sequence and processes it through 2 main sub-layers, each followed by a residual connection and layer normalization step. The encoder’s primary function is to encode input sequences, transforming raw data into context-aware representations. The structure of an encoder block is as follows:
-
multi-head self-attention: The input to the encoder block first goes through a multi-head attention sub-layer. In this self-attention mechanism, the queries, keys, and values are all derived from the output of the previous encoder layer (or the input embeddings with positional encoding in the first layer). This allows each position in the input sequence to attend to all other positions, capturing contextual dependencies. A padding mask is typically used to ignore padding tokens (which are used for sequence alignment)
-
Add & Norm: A residual connection is applied around the multi-head attention sub-layer, meaning the original input to the sub-layer is added to its output. This sum is then passed through a layer normalization layer, i.e.
-
Position-wise FFN: The output of the normalization step is then fed into a position wise feed forward networks sub-layer (2 linear layers with ReLU activation, dim expansion then compression 512 → 2048 → 512).
-
Second Add & Norm: Same as step 2, and provides final output for this encoder block
The data flow can be summarized as: Input Multi-Head Attention Add & Norm Position-wise FFN Add & Norm Output. The stacking of multiple such encoder layers
(6-12x) allows the model to learn increasingly complex representations of the input sequence.
Key features:
- Input: token embedding for sequence models + positional encoding
- Parallel processing: Unlike RNNs, encoders process entire sequences simultaneously
- All sub-layers maintain same dimension
Translation
Encodes
The cat sat on the matby:
- Embedding words + positional info
- Computing attention scores to understand relationships (e.g. “sat” → “cat”)
- Outputs contextual embeddings for the decoder or other downstream tasks
Related
- transformer decoder block
- BERT (encoder-only architecture)