Topics
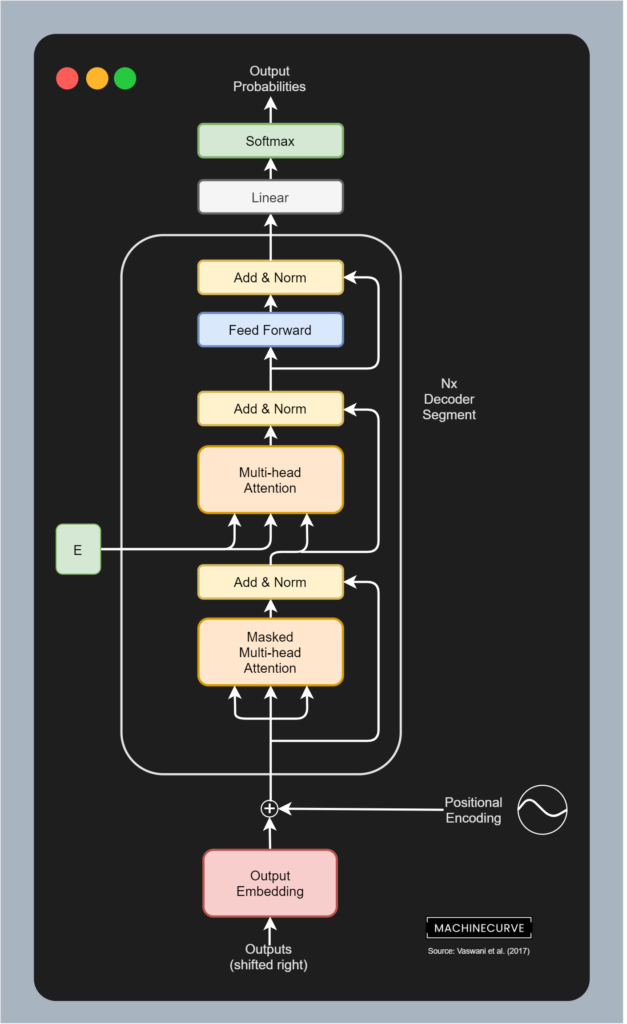
A Transformer decoder block is a key component of the Transformer’s decoder, responsible for generating the output sequence. Similar to the encoder, the decoder consists of a stack of identical layers. Each decoder layer has 3 main sub-layers, each followed by a residual connection and layer normalization step. Primary job is to generate output sequences based on the encoded inputs and previously generated outputs. The structure is:
- masked multi-head self-attention: The mask prevents the decoder from attending to subsequent tokens in the target sequence, ensuring that the prediction for the current position only depends on the tokens generated so far. This is essential for auto-regressive property. Padding masks are also used here
- Add & Norm: A residual connection and layer normalization are applied around the masked multi-head self-attention sub-layer
- Encoder-Decoder Multi-Head Attention: The second sub-layer is another multi-head attention mechanism, but this time, the queries () come from the output of the previous decoder sub-layer, while the keys () and values () come from the output of the final transformer encoder block (often referred to as the “memory”). This type of attention is also called as cross-attention. It allows the decoder to attend to the encoded input sequence and draw relevant information for generating the target sequence. Padding masks for the encoder output are applied here.
- Second Add & Norm: Another residual connection and layer normalization are applied around the encoder-decoder attention sub-layer.
- Position-wise Feed-Forward Network: The third sub-layer is a position wise feed forward networks, identical in structure to the one in the encoder (2 linear layer + ReLU activation)
- Third Add & Norm: A final residual connection and layer normalization are applied around the position-wise feed-forward network
The data flow in a decoder layer is: Input Masked Multi-Head Self-Attention Add & Norm Encoder-Decoder Multi-Head Attention Add & Norm Position-wise FFN Add & Norm Output.
Key features:
- Input: token embedding for sequence models + positional encoding (for the output generated so far)
- applies teacher forcing during training
- masked multi-head self-attention: Prevents attending to future positions, maintaining the auto-regressive property.
- During training, we have access to future generations as well, but by masking those indices, we prevent the model from cheating
- cross-attention: Allows the decoder to focus on relevant parts of the encoded inputs.
Example
In machine translation, for translating
The cat sat on the matto French:
- Decoder first outputs
Lebased on the encoded input English sentence- Embed previous outputs (
Lein this case) along with positional encoding- Use masked self-attention to focus on relevant outputs so far
- Use cross attention to focus on relevant encoded inputs (from encoder block)
- Generates
chatconsidering all prev outputs (Le) and the encoded inputs- Generation continues until
eos(end of sentence) token
Related
- transformer encoder block
- GPT (decoder-only architecture)