Topics
The idea to use MoE tuning with LLaVA architecture
The architecture is straightforward: Feed vision modality using CLIP as vision encoder + MLP. Feed text modality using word embeddings. Pass this through a standard transformer encoder block. The interesting part comes during the training/tuning of this architecture where we replicate the FFN layer inside the block and put a router in front of them (typical MoE layer intuition).
Diving deeper, the training/tuning is 3-staged:
- Stage 1: Only train the MLP; rest is frozen
- Stage 2: Train embeddings, MLP and the encoder block; vision encoder is frozen
- Stage 3: Replace standard encoder with MoE encoder and train, keeping everything frozen except the router and the FFN layers
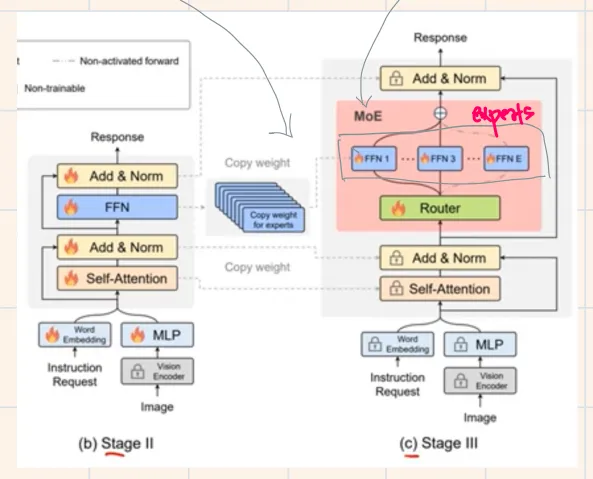
Few optimizations common across vision MoEs are also used here along with load balancing in MoE. Important thing to note is the use of soft-MoE instead of sparse MoE.