Topics
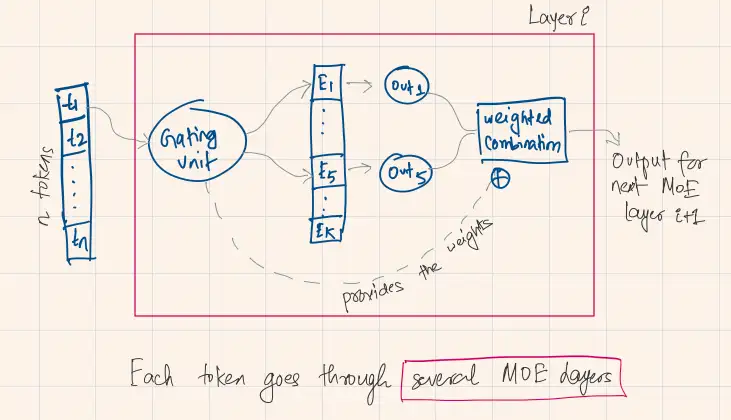
In the context of transformer, Sparse MoE layers are used instead of dense feed-forward network (FFN) layers. MoE layers have a certain number of “experts” (e.g. 8), where each expert is a neural network. In practice, the experts are FFNs, but they can also be more complex networks or even a MoE itself, leading to hierarchical MoEs!
In the diagram, we have the experts through and a gating mechanism aka router. Together they compose one MoE layer. We can stack such layers.