Topics
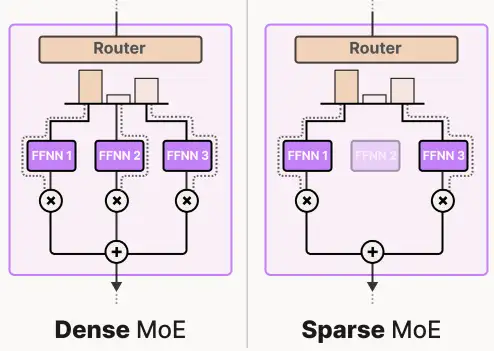
Sparse and Dense MoEs are basically similar in many aspects. The main difference is during token routing, where sparse only activates top-k experts per token (with k being 1 or 2), whereas in dense, all experts process each token. This effectively results in different computation costs and latencies. Nowadays, when we say MoE, we usually are talking about the sparse variant.
The motivation behind prsuing research in the direction of sparsity ⎯ scaling sparse params with fixed computation budget per example is independently useful since:
- Scaling laws: larger MoEs → better sample efficiency
- Sparsity: faster processing, since we are skipping certain params
Some modern architectures have variable sparsity via dynamic expert selection.