Topics
GShard from Google (2020) is a system which allows for scaling LLMs with MoEs. They were able to train 600 billion parameters efficiently on 2048 TPU v3 cores in 4 days.
It’s a module composed of a set of lightweight annotation APIs and an extension to the XLA compiler. It is proposed to enable large scale models with up to trillions of parameters.
In terms of model architecture, authors replace every other FFN layer with an MoE layer using top-2 gating in both the encoder and the decoder ⎯ in a top-2 setup, we always pick the top expert, but the second expert is picked with probability proportional to its weight.
With optimizations such as introducing auxiliary loss for load balancing in MoEs, fixed expert capacity and local dispatching, GShard is able to speed up the gating function and make training stable at the same time.
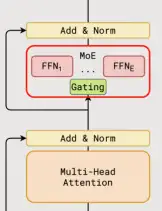
A nice result : Deeper models bring consistent quality gains across the board.