Topics
A vanilla approach to penalize imbalanced routing in MoEs.
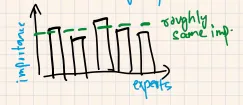
This loss ensures that all experts receive a roughly equal number of training examples.
def compute_aux_loss(router_probs, num_experts):
# Calculate fraction of tokens going to each expert
expert_usage = router_probs.mean(dim=0) # [num_experts]
# Compute variance from ideal uniform distribution
uniform_prob = 1.0 / num_experts
balance_loss = torch.sum((expert_usage - uniform_prob) ** 2)
return balance_lossIn sample code above, router_probs are weights generated during token routing.
Note
cross-entropy loss forces router to send tokens to better and accurate experts, but the auxiliary loss tries to even out the token routing across experts. We can control their influences by some weighing factors.