Topics
Core attention operation in transformer architectures. Computes weighted sum of values () based on query-key (, ) similarities:
Components:
- : What we’re looking for
- : What’s available to attend to
- : Actual content being weighted
- : Key/query dimension (scaling factor)
Q, K, V Derivation: , ,
- : input representation
- , , : learned weight matrices
The process is same as regular dot-product attention, but with added scaling for stability:
- Compute scores (pairwise similarities)
- Scale by (prevent gradient instability)
- Softmax → attention weights (probability distribution)
- Weighted sum:
scores = (Q @ K.T) / math.sqrt(d_k) # Score matrix
weights = F.softmax(scores, dim=-1) # Attention map
output = weights @ V # Weighted sum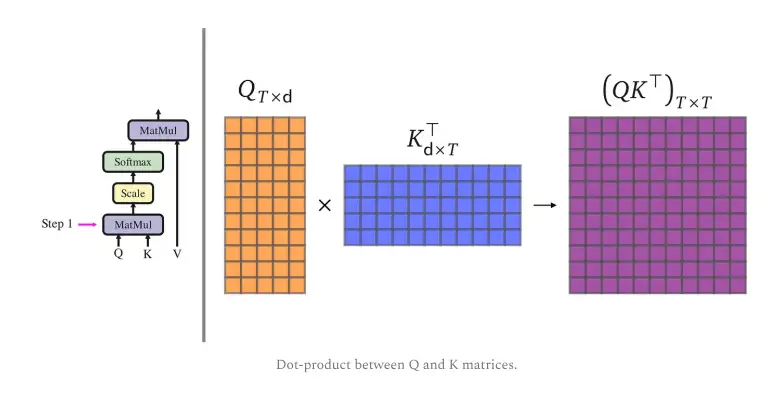
Note
Why scaling matters: Without , dot products grow large as dimensionality increases → softmax gradients vanish. Scaling maintains stable gradients.
Efficiency: Pure matrix ops → highly parallelizable (GPU-friendly).
Drawbacks: Complexity: O() with sequence length (L).
Related
- multi-head attention (extension using multiple parallel attention heads)
- self-attention (Q, K, V from same input)
- cross-attention (Q from decoder, K, V from encoder)