Topics
Let’s take the case of machine translation using encoder-decoder architecture where the output vocabulary consists of five elements: , with one representing the end-of-sequence token.
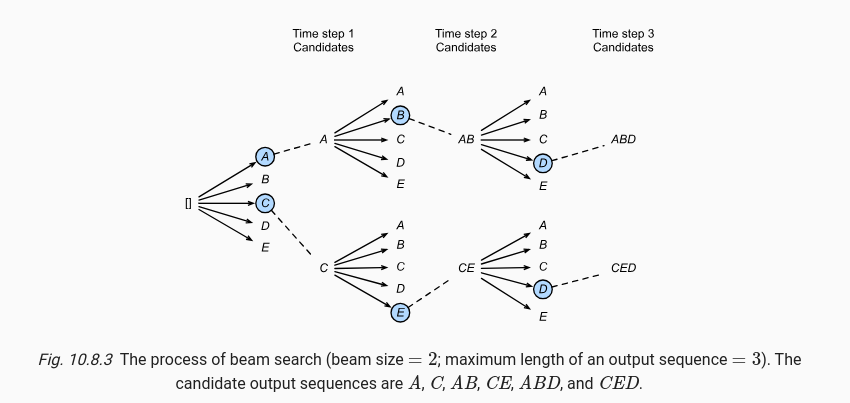
In this example, the beam size is set to 2, and the maximum output sequence length is 3. At time step 1, the algorithm begins with an empty sequence and selects the two tokens with the highest conditional probabilities , which are and . Here, represents the context or input.
Moving to time step 2, the algorithm expands each of these initial tokens by considering all possible next tokens . It computes the probabilities:
From these ten possibilities, it selects the two sequences with the highest probabilities, shown in the diagram as and .
At the final time step 3, the process repeats. For each of the two sequences from step 2, it computes:
Again, it selects the two highest probability sequences, resulting in and as the final candidates and choose the one which maximizes the following score:
The above score is just log likelihood, but with the additional beam search normalization factor.