Topics
Since MoE fine-tuning is difficult (same for training), as they overfit easily, heavy regularization is used.
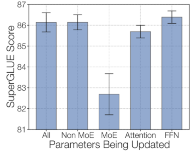
For by only freezing the MoE layers, we can speed up the training while preserving the quality
Also, few tips:
- Lower batch size
- Increase learning rate
- instruction tuning works well for MoEs
- Tune for larger (or more number of) tasks
- Scaling experts yield better sample efficiency, but diminishing gains beyond 256
- Stability via expert capacity and load balancing in MoE
Expert Parallelism
MoEs are tricky to parallelize, so distribute the experts across workers.