Topics
“8x7B” name is a bit misleading because it is not all 7B params that are being 8x’d, only the FeedForward blocks in the transformer are 8x’d, everything else stays the same. Hence also why total number of params is not 56B but only 46.7B ~ 47B.
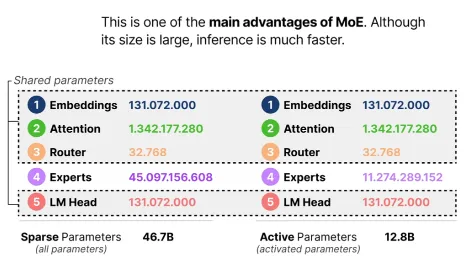
When Mixtral receives a request, the model’s router component picks 2 of the model’s 8 experts to handle the request. While all 46.7B parameters are loaded into the memory, only 12.9B are used during inference, as the attention layers are shared.