Topics
Word-based tokenization is a simple form of tokenization where we break text into units (“tokens”) by splitting on whitespace and punctuation, so that each token corresponds roughly to a “word” or standalone symbol. Used in early NLP pipelines.
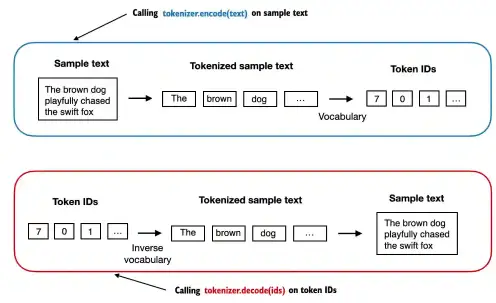
Pros:
- Intuitive: Words are natural semantic units that humans understand
- Preserves meaning: Each token represents a complete semantic unit
- Simplicity: Implementation is straightforward (e.g., splitting on spaces and punctuation)
- Interpretability: Tokens directly correspond to words in the vocabulary
- Smaller sequence lengths: Compared to character tokenization
Cons:
- Large vocabulary size: Requires storing many tokens, increasing model size
- Out-of-vocabulary (OOV) issues: Cannot handle unseen words without special handling
<unk>token - Inefficient for rare words: Dedicates vocabulary slots to infrequent terms
- Language-specific: Different languages require different tokenization rules
- Morphological variations: Different forms of the same word (
run/running/runs) need separate tokens - Compound words: Struggles with languages that combine words (like German)
import re
class WordTokenizer:
def __init__(self, texts, add_special_tokens=True):
# Build vocabulary from a list of texts
tokens = []
for text in texts:
tokens.extend(self._tokenize(text))
vocab = sorted(set(tokens))
if add_special_tokens:
vocab.extend(["<|endoftext|>", "<|unk|>"])
self.str_to_int = {token: idx for idx, token in enumerate(vocab)}
self.int_to_str = {idx: token for token, idx in self.str_to_int.items()}
self.unk_token = "<|unk|>"
def _tokenize(self, text):
# Split on whitespace and common punctuation
tokens = re.split(r'([,.:;?_!\"()\'\-\-]|\s)', text)
return [t.strip() for t in tokens if t.strip()]
def encode(self, text):
tokens = self._tokenize(text)
return [self.str_to_int.get(token, self.str_to_int[self.unk_token]) for token in tokens]
def decode(self, ids):
tokens = [self.int_to_str.get(idx, self.unk_token) for idx in ids]
text = " ".join(tokens)
# Remove spaces before punctuation for readability
text = re.sub(r'\s+([,.:;?_!\"()\'\-\-])', r'\1', text)
return text
def vocab_size(self):
return len(self.str_to_int)