Topics
nn.Embedding is nothing but a lookup table.
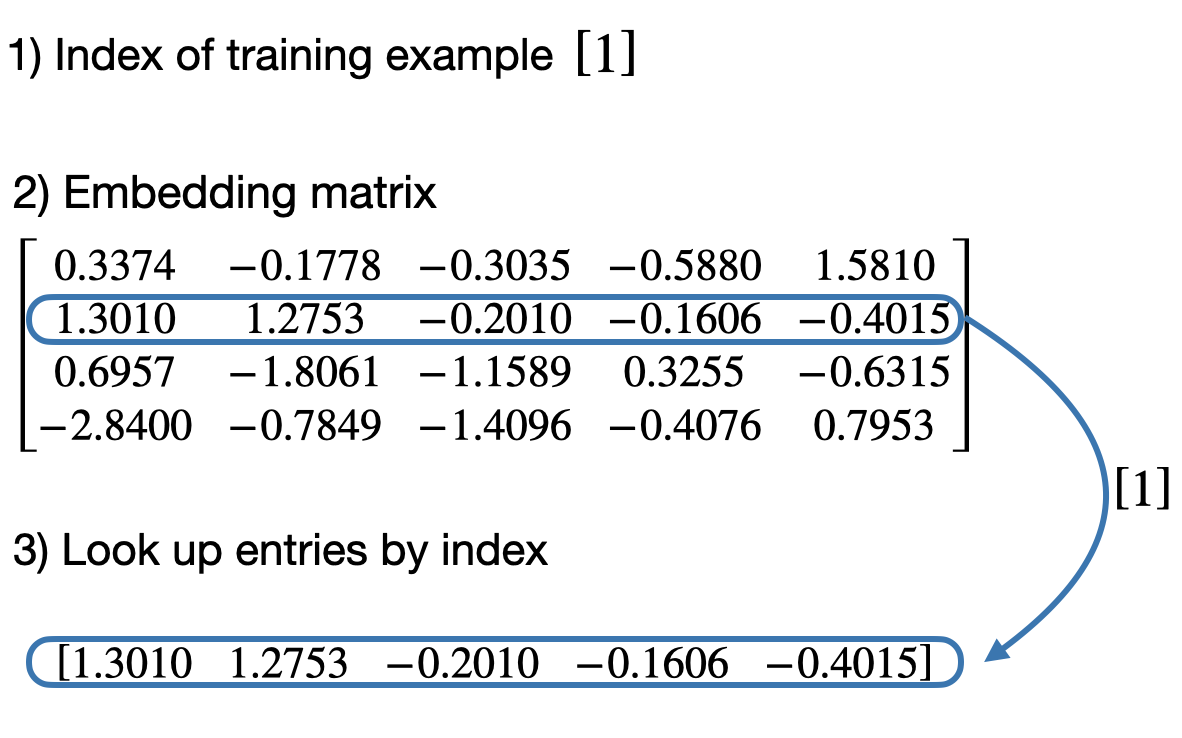
The embedding layer above accomplishes exactly the same as
nn.Linearlayer (without bias term) on a one-hot encoded representation in PyTorch.
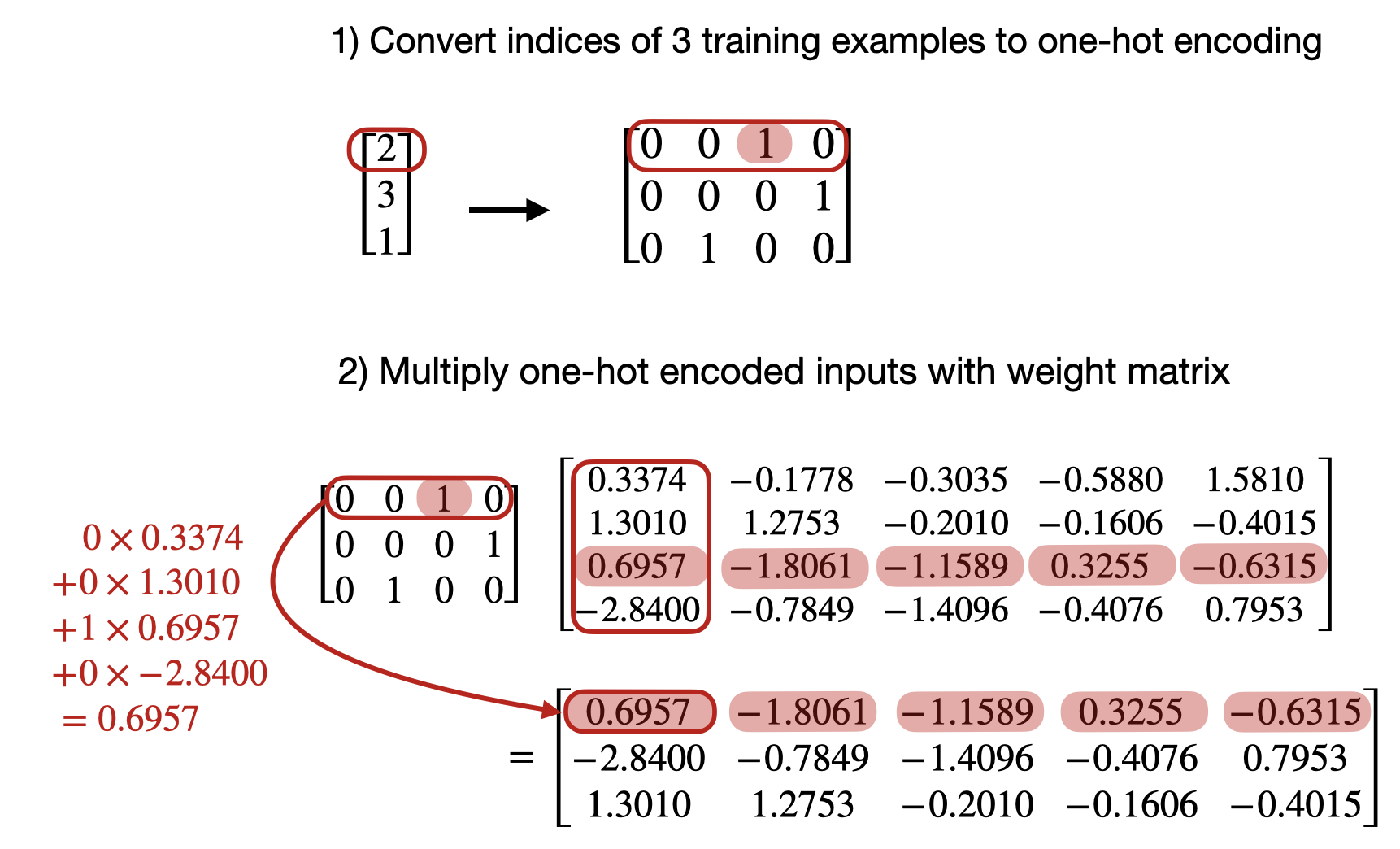
Since all but one index in each one-hot encoded row are 0 (by design), this matrix multiplication is essentially the same as a look-up of the one-hot elements.
V=4
dims=5
embedding = torch.nn.Embedding(V, dims)
linear = torch.nn.Linear(V, dims, bias=False)
print(embedding.weight.shape) # torch.Size([4, 5])
print(linear.weight.shape) # torch.Size([5, 4])To make an apples to apples comparison, let’s have the weights equal in them
linear.weight = torch.nn.Parameter(embedding.weight.T)For linear layer, we need input to be one-hot encoded
idx = torch.tensor([2, 3, 1])
onehot_idx = torch.nn.functional.one_hot(idx)Comparing the results:
res_linear = linear(onehot_idx.float())
res_emb = embedding(idx)
torch.allclose(res_linear, res_emb) # TrueThus, we see nn.Embedding and nn.Linear (without bias term) work the same.