Topics
There are broadly 2 ways: Extrinsic and Intrinsic evaluation.
In Extrinsic evaluation, we evaluate the downstream task such as text-classification or named entity recognition, using metrics such as F1 score, accuracy etc. The big advantage is that we are evaluating our embeddings in the setting where it will be used, while the drawback is that this can be slow and other influencing factors need to be taken into account.
In Intrinsic evaluation, we have 2 subclasses:
- Word analogy tasks
man:woman :: king:?- Basically, we find the word with vector closest to . In the example here, it’s expected to be close to
queen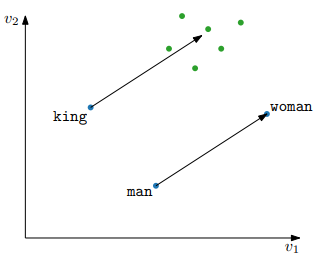
- Fails when information is not be encoded linearly in the embeddings
- Correlation with human judgements
- Grab few pairs of words and have humans score how similar they are. Call this
SET 1. For the same pair of words, calculate their cosine similarity based on word embeddings. Call thisSET 2. Find the correlation between the two sets using spearman’s rank correlation coefficient - High correlation indicates that our embeddings are good and match human judgements
- This approach is very subjective since humans are used for
SET 1 - GloVe 42B model performs very well in this, with 75.9% correlation
- Grab few pairs of words and have humans score how similar they are. Call this